Having actually done this now, I can say that the most critical corrections (at least on my system) were in the lower frequency ranges, and could in theory be handled by the mic input. Okay, one would have to still work on the highest stuff by hand, but it would certainly be a great start.
Since Genixia's already done some work with sending commands to the equalizer, I could see this being made to work. You could run a userland app to have it do the analysis and it could spit out a set of EQ settings that you could transcribe into the real equalizer.
There would be two huge stumbling blocks in the code however:
1) The analysis algorithm. Having worked with RTA software now, I can see that a given frequency doesn't simply "sit there", it jitters quite a bit and you need to do either averaging or peak-holding to get a decent reading. I found I got the flattest and most accurate results with peak-holding on my system.
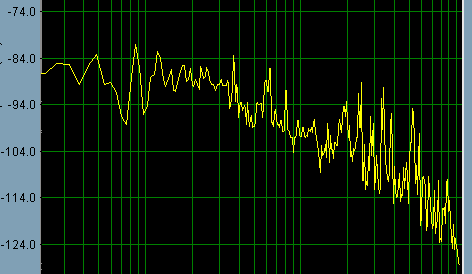
2) The algorithm that decides what corrections to make to the EQ. With only X number of bands to use, it has to make compromises, it can't correct every tiny little thing. The trick is coding it to "know" what a given correction will do to the waveform, then do the best-fit algorithm. This is not going to be an easy task. Take this example frequency graph:

You tell me how to code an algorithm to flatten that using only 8 parametric EQ bands.




 Previous Topic
Previous Topic Index
Index
{kind=link}